
|
|
|
|
|
|
|
||||||||||||||||||||||||||||
|
|
|
||||||||||||||||||||||||||||||
|
|
|
Oracle Instances and DatabasesTwo entities are sometimes referred to as an Oracle database—the instance and the database—and people often confuse them. In the Oracle world, the term database refers to the physical storage of information, while instance refers to the software executing on the server that provides access to the information in the database. The instance runs on the computer or server; the database is stored on the disks attached to the server, as shown in Figure 1-1. Figure 1-1. An instance and a database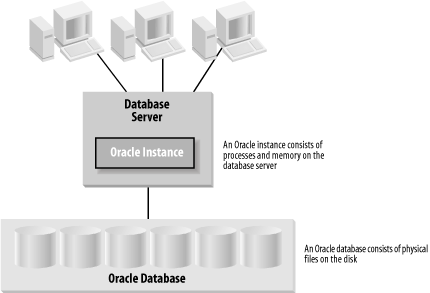
The database is physical: it consists of files stored on disks. The instance is logical: it consists of in-memory structures and processes on the server. An instance can connect to one and only one database. Instances are temporal, but databases, with proper maintenance, last forever.
Users do not directly access the information in an Oracle database. Instead, they pass requests for information to an Oracle instance.
The Components of a DatabaseA database consists of a collection of physical files and logical structures, described in the following sections. A database has a specific name, assigned when you create it. You cannot change the name of a database once you have created it, although you can change the name of the instance that accesses the database. TablespacesA tablespace is a logical structure, which exists only within the context of an Oracle database. Each tablespace is composed of physical structures called datafiles; each tablespace must consist of one or more datafiles, and each datafile can belong to only one tablespace. When you create a table, you can specify the tablespace in which you want to create it. Oracle will then find space for it in one of the datafiles that make up the tablespace.
Figure 1-2 shows the relationship of tablespaces to datafiles for a database. This figure shows two tablespaces within an Oracle database. When you create a new table in this Oracle database, you may place it in the DATA1 tablespace or the DATA2 tablespace. It will physically reside in one of the datafiles that make up the specified tablespace. Figure 1-2. Tablespaces and datafiles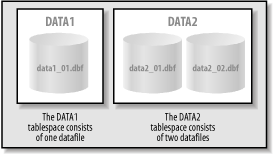 Physical Files in an Oracle DatabaseA tablespace is a logical view of the physical storage of information in an Oracle database. Three fundamental types of physical files make up an Oracle database:
Other files, such as password files and instance initialization files, are used within a database environment, but the three fundamental types listed represent the physical database itself. Figure 1-3 illustrates the three types of files and their interrelationships. Figure 1-3. The files that make up a database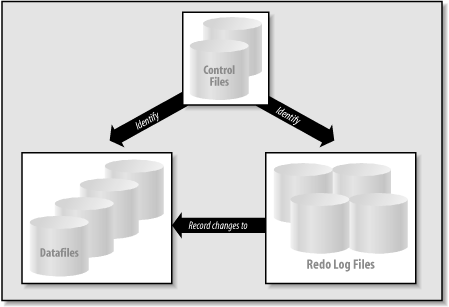
Oracle9i introduces the concept of Oracle managed files (OMFs). You indicate that you want to use OMFs by specifying values for the initialization parameters DB_CREATE_FILE_DEST and DB_CREATE_ONLINE_LOG_DEST_n (these and all of the Oracle initialization parameters are described in detail in Chapter 2). If you request OMFs, Oracle9i will automatically create, name, and delete (when appropriate) all the files for your Oracle database. OMFs are designed to reduce the maintenance overhead of naming and tracking the names for your Oracle database, as well as to avoid the problems that can occur when fallible human beings do not correctly identify a file in an Oracle database. The following sections describe the role of these three types of files and their interactions. Control FilesThe control file contains a list of all the other files that make up the database, such as the datafiles and redo log files. It also contains key information about the contents and state of the database, such as:
Prior to Oracle8, control files were typically under a megabyte in size. With Oracle8, there is more information in the control file, such as the details of database backups. The control files in Oracle8 and beyond can easily grow to the 10 MB range or beyond. The size of a control file is influenced by a number of initialization parameters, including MAXLOGFILES, MAXLOGMEMBERS, MAXLOGHISTORY, MAXDATAFILES, and MAXINSTANCES.
You can have your Oracle instance maintain multiple copies of control files. Although you can potentially rebuild a control file if it is damaged or deleted, this process takes time and in some scenarios you cannot rebuild the control file to its correct state. You cannot run an Oracle database without a control file, so having multiple copies of your control file can be an important safety option. You use the initialization parameter CONTROL_FILES to list the locations of multiple copies of the control file. DatafilesDatafiles contain the actual data stored in the database. This data includes the tables and indexes created by users of the database; the data dictionary, which keeps information about these data structures; and the rollback segments, which are used to implement Oracle's consistency scheme.
A datafile is composed of Oracle database blocks that are, in turn, composed of operating system blocks on a disk. Oracle block sizes range from 2K to 32K. If you're using Oracle with very large memory (VLM) support, you may use big Oracle blocks (BOBs), which can be as large as 64K in size.
Prior to Oracle9i, you could have only a single block size for an entire database. With Oracle9i, you still set a default block size for the database, but you can also have five different nonstandard block sizes in the database. Each datafile can support only one block size, but you can have mixed block sizes within the database.
Figure 1-4 illustrates the relationship of Oracle blocks to operating system blocks. Figure 1-4. Oracle blocks and operating system blocks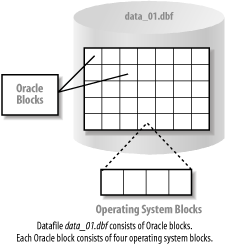
Datafiles belong to only one database and to only one tablespace within that database. Data is read in units of Oracle blocks from the datafiles into memory as needed, based on the work users are doing. Blocks of data are written from memory to the datafiles stored on disk, as needed, to ensure that the database reliably records changes made by users.
Datafiles are the lowest level of granularity between an Oracle database and the operating system. When you lay a database out on the I/O subsystem, the smallest physical piece you place in any particular location is a datafile. Tuning the I/O subsystem to improve Oracle performance typically involves moving datafiles from one set of disks to another. Datafile structureThe first block of each datafile is called the datafile header. It contains critical information used to maintain the overall integrity of the database. One of the most crucial pieces of information in this header is the checkpoint structure, a logical timestamp that indicates the last point at which changes were written to the datafile. This timestamp is critical for recovery situations. The Oracle recovery process uses the timestamp in the header of a datafile to determine which redo logs to apply to bring the datafile up to the current point in time. Extents and segmentsFrom a physical point of view, a datafile is stored as operating system blocks. From a logical point of view, datafiles have three intermediate organizational levels: data blocks, extents, and segments. An extent is a set of data blocks that are contiguous within an Oracle datafile. A segment is an object that takes up space in an Oracle database, such as a table or an index, that is comprised of one or more extents.
When Oracle updates data, it attempts to update the data in the same data block. If there is not enough room in the data block for the new information, Oracle will write the data to a new data block, which may be in a different extent. Redo Log FilesRedo log files store a "recording" of the changes made to the database as a result of transactions and internal Oracle activities. In its normal operations, Oracle caches changed blocks in memory; in the event of an instance failure, some of the changed blocks may not have been written out to the datafiles. The recording stored in the redo log can be used to play back the changes that were lost when the failure occurred. Multiplexing redo log filesOracle uses specific terminology in describing the management of redo logs. Each Oracle instance records the changes it makes to the database in redo logs. You can have one or more redo logs, referred to as redo log members, in a redo log group.
Logically, you can think of a redo log group as a single redo log file. However, Oracle allows you to specify multiple copies of a redo log to protect the log against media failure. Multiple copies of the same log are grouped together in a redo log group. All redo log groups for an instance are referred to as a redo thread.
There are ways you can rebuild the static part of the control file if you lose it, but there is no way to reproduce a lost redo log file; be sure that you have multiple copies of the redo file. How Oracle uses the redo logsOnce Oracle fills one redo log file, it automatically begins to use the next log file. Once the server cycles through all the available redo log files, it returns to the first one and reuses it. Oracle keeps track of the different redo logs by using a sequence number. As the server fills each redo log file and moves on to the next one, it increments an internal counter called the redo log sequence number. This sequence number is recorded inside the redo log files as they are used. Oracle uses this internal number to properly sequence the logs, even though a reused log file may have the name initially created for an earlier redo log. Archived redo logsWhile reading the previous explanation, you might have wondered how to avoid losing the critical information in the redo log when Oracle cycles over a previously used redo log.
There are actually two ways to address this issue. The first is quite simple: you don't avoid losing the information, and you suffer the consequences in the event of a failure. You will lose the history stored in the redo file when it's overwritten. If a failure occurs that damages the datafiles, you must restore the entire database to the point in time when the last backup occurred. No redo log history exists to reproduce the changes made since the time the last backup occurred, so you will be out of luck. Very few Oracle shops make this choice, because the inability to recover to the point of failure is unacceptable—it results in lost data.
The second and more practical way to address the issue caused by recycling redo logs is to archive the redo logs as they fill. To understand archiving redo logs, you must first understand that there are actually two types of redo logs for Oracle:
The operating system files that Oracle cycles through to log the changes made to the database
An Oracle database can run in one of two modes with respect to archiving redo logs: NOARCHIVELOG
ARCHIVELOG
To enable ARCHIVELOG mode, you must turn on archive logging with the ALTER DATABASE ARCHIVELOG command in SQL*Plus and set the LOG_ARCHIVE_START initialization parameter to TRUE. This will start archiving logs to the location specified by the LOG_ARCHIVE_DEST parameters with names specified by the LOG_ARCHIVE_FORMAT parameter.
1.3 The Components of an InstanceAn Oracle instance can be defined as an area of shared memory and a collection of background processes. The area of shared memory for an instance is called the System Global Area, or SGA. The SGA is not really one large undifferentiated section of memory—it's made up of various components described in the next section, "Memory Structures for an Instance." All the processes of an instance—system processes and user processes—share the SGA. Prior to Oracle9i, the size of the SGA was set when the Oracle instance started. The only way you could change the size of the SGA or any of its components was to change the appropriate initialization parameters and stop and restart the instance. With Oracle9i, you can now change the size of the SGA or its components while the Oracle instance is still running. The background processes interact with the operating system and each other to manage the memory structures for the instance. These processes also manage the actual database on disk and perform general housekeeping for the instance. Other physical files can be considered as part of the instance as well:
Additional background processes may exist when you use certain other features of the database: for example, the Shared Server/Multi-Threaded Server (MTS), job queues, or replication. 1.3.1 Memory Structures for an InstanceThe SGA is actually composed of four main areas: the database buffer cache, the shared pool, the redo log buffer, and the large pool, as shown in Figure 1-5. Figure 1-5. An Oracle instance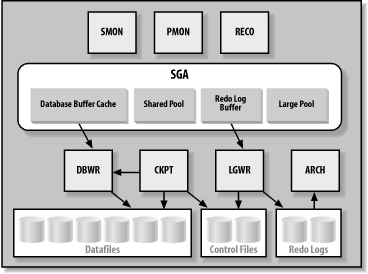 1.3.1.1 Database buffer cacheThe database buffer cache caches blocks of data retrieved from the database. This buffer between the users' requests and the actual datafiles improves the performance of the Oracle database. If a piece of data can be found in the buffer cache, you can retrieve it from memory without the overhead of having to go to disk. Oracle manages the cache using a least recently used (LRU) algorithm. This means that if a user requests data that has been recently used, the data is more likely to be in the database buffer cache and can be delivered immediately without having to execute a disk read operation. Oracle7 had one pool of buffers for database blocks. Oracle8 introduced multiple buffer pools. Three pools are available in Oracle8 and beyond:
Both the KEEP and the RECYCLE buffer pools remove their objects from consideration by the LRU algorithm. You can mark a table or index for caching in a specific buffer pool. This helps to keep more desirable objects in the cache and avoids the "churn" of all objects fighting for space in one central cache. 1.3.1.2 Shared poolThe shared pool caches various constructs that can be shared among users. For example, SQL statements issued by users are cached so that they can be reused if the same statement is submitted again. Another example is stored procedures— pieces of code stored and executed within the database. These are loaded into the shared pool for execution and then cached, again using an LRU algorithm. The shared pool is also used for caching information from the Oracle data dictionary, which is the metadata (or data describing data structures) that describes the structure and content of the database itself. 1.3.1.3 Redo log bufferThe redo log buffer caches redo information until it is written to the physical redo log files stored on a disk. Use of this buffer improves performance. Oracle caches the redo until it can be written to disk at a more optimal time, which avoids the overhead of constantly writing to the disk with the redo logs. 1.3.1.4 Large poolThe large pool, introduced with Oracle8, is an optional area of the SGA used for buffering I/O for various server processes, including those used for backup and recovery. The area is also used to store session memory for the Multi-Threaded Server and when using the XA protocol for distributed transactions. 1.3.2 Background Processes for an InstanceThe background processes shown in Figure 1-5 are:
1.4 Oracle VersionsOracle version numbers, like the product packaging we discuss in the next section, have more to do with the marketplace than the technology. The Oracle database, like all software products, has a periodic release cycle, but the exact timing and contents of those releases is shaped, to some degree, by sales requirements as well as the development cycle. Because of nontechnical factors, the naming conventions for versions can change at any time. As of this writing, Oracle seems to have settled on a consistent version naming scheme. Up until Oracle8, each major version was named with an increasing version number (e.g., Oracle6, Oracle7, Oracle8). However, the release after Oracle8 was named Oracle8i, connecting it with the Internet (and causing formatting problems for authors ever since!). The next version was named Oracle9i, and the upcoming version is slated to be called Oracle10i—although that may change by the time the version is released. Typically, the OracleNi versions have had an intermediate release, also typically identified as Release 2. Release 2s generally are the first major maintenance release; they follow the main release and frequently contain enhancements that were planned for the main release but that could not make the deadline. This book assumes that Oracle8 was the beginning of time. Any features that were not present in that version are not discussed. Any features that were added or dropped since then are duly noted.
1.5 Oracle PackagingEven more so than versions, the actual packaging of Oracle releases is controlled primarily by sales forces, rather than by technical forces. The decision to include a feature in one or more versions of the database, as well as the decision to segregate functionality in an extra-cost option, is, for the most part, arbitrary. 1.5.1 EditionsThere are four basic editions of the Oracle database:
Although Oracle sometimes decides to fold formerly extra-cost options into one or more editions of the standard product, the company has never yet decided to take functionality out of a lesser edition in order to force upgrades. Most of the functionality described in this book is included in all versions of the database. The following functionality is available in Enterprise Edition, but not Standard Edition, as of the time of this writing:
1.5.2 OptionsOracle provides a number of options that can be purchased with Oracle Enterprise Edition. As with the packaging in general, the content, price, and availability of these options are subject to change. At the time of this writing (with Oracle9i Release 2), the following options are available:
|
|
||||||||||||||||||||||||||||
|
|
|
Copyright © 2003 Tony Hogan |
|
||||||||||||||||||||||||||||